[OSC] Day5: Memory Management (Non-contiguous memory management part)
Memory Management
Because the content is too much, we’ll divide it into 6 parts.
Memory Management 1

OS responsibility
- Allocate/deallocate memory when requested by processes, keep track of used/unused memory
- Distribute memory between processes and simulate an “infinitely large” memory space
- Control access when multiprogramming is applied
- Transparently move data from memory to disk and vice versa
Models(Contiguous & Non-contiguous)
Contiguous memory management models allocate memory in one single block without any holes or gapsNon-contiguous memory management models are capable of allocating memory in multiple blocks, or segments, which may be placed anywhere in physical memory (i.e., not necessarily next to each other)
Partitioning
Mono-programming: one single partition for user processes
No memory abstractionFor mono-programming, every process is allocated contiguous block of memory, i.e. it contains no “holes” or “gaps” (⇔ non-contiguous allocation)
Only one single user process is in memory/executed at any point in time (no multi-programming)
A fixed region of memory is allocated to the OS/kernel, the remaining memory is reserved for a single process (MS-DOS worked this way)
This process has direct access to physical memory (i.e. no address translation takes place)
One process is allocated the entire memory space, and the process is always located in the same address space
No protection between different user processes required (one process)
Overlays enable the programmer to use more memory than available (burden on programmer)
What is “Overlays”?Disadvantages:
the process of transferring a block of program code or other data into internal memory, replacing what is already stored
Because some codes or data will be used frequently but some are not. So frequently used data will be stored in internal memory and non-frequently used data will be stored in external memory. When non-frequently used data is used, it will be moved to replace internal memory.

For example in the above image, CPU can execute neither B or C so we can store B in the actually memory.
Overlay is to use time to exchange memory space
An embedded system would normally use overlays because of the limitation of physical memory, which is internal memory for a system-on-chip, and the lack of virtual memory facilities.
- Since a process has direct access to the physical memory, it may have access to OS memory
- The operating system can be seen as a process - so we have two processes anyway
- Low utilisation of hardware resources (CPU, I/O devices, etc.)
- Mono-programming is unacceptable as multiprogramming is expected on modern machines
But mono-programming can simulate multi-programming through swapping
Swap process out to the disk and load a new one (context switches would become time consuming)
Apply threads within the same process (limited to one process)
Why multi-programming —CPU Utilisation
There are n processes in memory, a process spends p precent of its time waiting for I/O.CPU Utilisation is calculated as 1 minus the time that all processes are waiting for I/O:
e.g. p = 0.9 then CPU Utilisation = 1 - 0.9 = 0.1
Because there might be more than 1 process, so the CPU Utilisation is 1- p^n
Therefore, CPU utilisation goes up with the number of processes and down for increasing levels of I/O
so the questions is why multi-programming can increase CPU Utilisation?
Assume we can have a computer which have 1 megabyte of memory.
If OS takes up 200k, leaving room for four 200k processes.
Now if we have I/O wait time of 80%, CPU Utilisation is (1-0.8^4) = 0.59 = 59% ==>not high
But if we have more memory, which we can have more processes, the number will increase
What if we add another megabyte of memory?
Multi-programming does enable to improve resource utilisation ⇒ memory management should provide support for multi-programming
Fixed Partitions of equal size
Divide memory into static, contiguous and equal sized partitions that have a fixed size and fixed location- Any process can take any (large enough) partition
- Allocation of fixed equal sized partitions to processes is trivial
- Very little overhead and simple implementation
- The OS keeps a track of which partitions are being used and which are free
Disadvantages:
Low memory utilisation and internal fragmentation: partition may be unnecessarily large
Overlays must be used if a program does not fit into a partition
What is internal fragmentation?
For example, memory can only be provided to programs in chunks divisible by 4, 8 or 16, and as a result if a program requests perhaps 23 bytes, it will actually get a chunk of 32 bytes. When this happens, the excess memory goes to waste. The waste is called internal fragmentation
Fixed Partitions of non-equal size
Now the partitions is non-equal, might be like 2M, 4M, 6M, 10M, etcIt reduces internal fragmentation
The allocation of processes to partitions must be carefully considered
So what about the allocation method?(private queue or shared queue)
One private queue per partition:- Assigns each process to the smallest partition that it would fit in
- Reduces internal fragmentation
- reduce memory utilisation(e.g. lots of small jobs result in unused large partition) and result in starvation
A single shared queue for all partitions can allocate small processes to large partitions but results in increased internal fragmentation
Memory Management 2
Relocation and Protection
Relocation: when a program is run, it does not know in advance which partition/addresses it will occupy- The program cannot simply generate static addresses (e.g. jump instructions) that are absolute
- Addresses should be relative to where the program has been loaded
- Relocation must be solved in an operating system that allows processes to run at changing memory locations
Address types
A logical address is a memory address seen by the process- It is independent of the current physical memory assignment
- It is, e.g., relative to the start of the program(always start with 0)
So when we do this address translation?
we have 3 options:
1. Static “relocation” at compile time: a process has to be located at the same location every single time (impractical because we don’t access directly to physical memory)
2. Dynamic relocation at load time: An offset is added to every logical address to account for its physical location in memory. Also slown down the loading of a process, does not account for swapping
3. Dynamic relocation at runtime(best way)
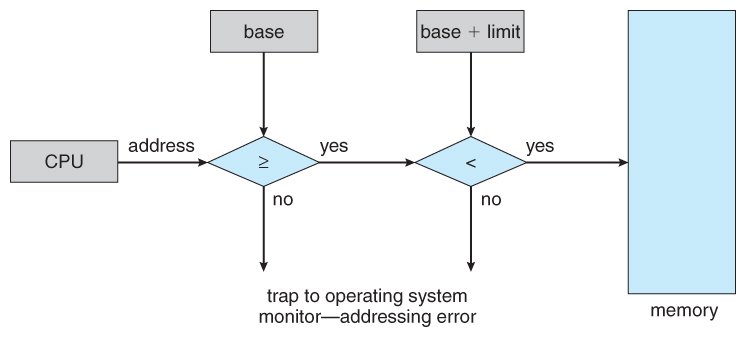
At Runtime: Base and limit registers
Two special purpose registers are maintained in the CPU (the MMU), containing a base address and limit- The base register stores the start address of the partition
- The limit register holds the size of the partition
- The base register is added to the logical (relative) address to generate the physical address
- The resulting address is compared against the limit register
This approach requires hardware support (was not always present in the early days!)
Dynamic Partitioning
Fixed partitioning results in internal fragmentation:- An exact match between the requirements of the process and the available partitions may not exist
- The partition may not be used entirely
- A variable number of partitions of which the size and starting address can change over time
- A process is allocated the exact amount of contiguous memory it requires, thereby preventing internal fragmentation

But it is not the solution for all multi-programming problems.
Assume now we have a process 4 which takes up 20M, it has to wait until some process ends. But process 1 is always waiting for I/O and do nothing, so we can use swapping!
Swapping
Swapping holds some of the processes on the drive and shuttles processes between the drive and main memory as necessaryDisadvantage:1. The exact memory requirements may not be known in advance (heap and stack grow dynamically) 2. External Fragmentation
External Fragmentation:
Swapping a process out of memory will create “a hole”, new process may not use the entire “hole”, leaving a small unused block
It is the fragmentation which is unused between process and process

Memory Compaction
So how to solve external fragmentation?We can use memory compaction.
It is a technique to move all the process together and move all holes up to another side.
It gonna solve our problem but it is time-consuming
The overhead of memory compaction to recover holes can be prohibitive and requires dynamic relocation
Since there are unused holes, how to keep track of available memory?(Linked lists & Bitmaps)
Linked Lists

A linked list consists of a number of entries (“links”!)
Each link contains data items, e.g. start of memory block, size, free/allocated flag
Each link also contains a pointer to the next in the chain
The allocation of processes to unused blocks becomes non-trivial
Bitmaps

advantage: small storage space
disadvantage: to find a group of 0 is time consuming and long operation
Memory is split into blocks of say 4K size
- A bit map is set up so that each bit is 0 if the memory block is free and 1 is the block is used, e.g.
32MB memory = 32MB/4KB = 32*1024/4 = 8192bitmap entires
8192 bits occupy 8192/8 = 1 KB storage(Small)
Memory management 3
Allocating Available memory algorithms(Dynamic partitioning management with Linked lists)
First Fit
starts scanning from the start of the linked list until a link is found which represents free space of sufficient size- If requested space is the exact same size as the “hole”, all the space is allocated
- Else, the free link is split into two: the first entry is set to the size requested and marked “used”; the second entry is set to remaining size and marked “free”
Next Fit
The next fit algorithm maintains a record of where it got to:- It restarts its search from where it stopped last time
- It gives an even chance to all memory to get allocated(First fit concentrates on the starts of the lists)
However, simulations have shown that next fit actually gives worse performance than first fit!
Best Fit
The best fit algorithm always searches the entire linked list to find the smallest hole big enough to satisfy the memory request- It is slower than first fit
- It also results in more wasted memory (because memory is more likely to fill up with only tiny useless holes)
Worst Fit
Because best fit will created the tiny holes which is more wasted memory, so there exists worst fit.The worst fit algorithm finds the largest available empty partition and splits it
- The left over part will still be large (and potentially more useful)
- Simulations have also shown that worst fit is not very good either!
Quick Fit
Quick fit maintains lists of commonly used sizes- For example a separate list for each of 4K, 8K, 12K, 16K, etc., holes
- Odd sizes can either go into the nearest size or into a special separate list
Similar to best fit, it has the problem of creating many tiny holes
Finding neighbours for coalescing (combining empty partitions) becomes more difficult/time consuming
Coalescing
Coalescing (joining together) takes place when two adjacent entries in the linked list become freeBoth neighbours are examined when a block is freed
- If either(or both) are also free
- Then the two(or three) entries are combined into one larger block by adding up the sizes
Summary
So far we have finish the contiguous allocation schemes!Different contiguous memory allocation schemes have different advantages/disadvantages
- Mono-programming is easy but does result in low resource utilisation
- Fixed Partitioning facilitates multi-programming but results in internal fragmentation
- Dynamic Partitioning facilitates multi-programming, reducing internal fragmentation but results in external fragmentation (allocation methods, coalescing, and compacting help)
Non-Contiguous memory allocation–Paging
Paging uses the principles of fixed partitioning and code re-location to devise a new non-contiguous management scheme:- Memory is split into much smaller blocks and one or multiple blocks are allocated to a process
- These blocks do not have to be contiguous in main memory, but the process still perceives them to be contiguous
- Internal Fragmentation is reduced to the last blcok only
- There is no external fragmentation, since physical blocks are stacked directly onto each other in main memory
Further information about contiguous memory management will be discussed in the next day's blog



评论
发表评论